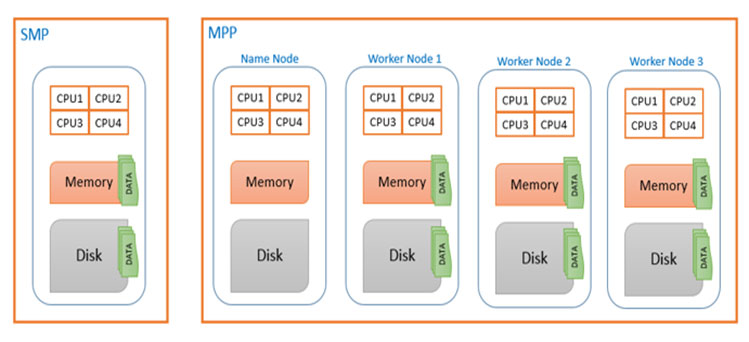
데이터 스토리지 변천사 (from SMP to MPP)
데이터를 안정적이고 비용 효율적으로 저장하고자 하는 요건은 컴퓨터의 탄생 시점부터 존재해 왔습니다. 1990년대 후반까지 이러한 요건을 만족시키는 장기적인 데이터 저장소는 대용량의 고성능 고비용 스토리지였습니다. 이러한 접근 방식은 정보화 수준이 높아지고 빅데이터 시대에 가까워지면서 데이터의 양이 폭발적으로 증가하고 데이터에 대한 수요가 늘어나자 점차 심각한 문제를 드러내기 시작합니다
가장 큰 문제는 비용입니다. 저장해야 할 데이터의 양이 폭발적으로 늘어난 데다 어플리케이션의 수와 종류도 늘어나 스토리지의 증설과 신규도입 비용이 IT 예산에서 너무나 큰 비중을 차지하게 되었습니다. 스토리지 가상화를 통한 씬 프로비져닝 (Thin provisioning) 을 적용해 스토리지 가용률을 높이는 데에도 한계가 발생할 수밖에 없었습니다.
두번째 문제는 성능입니다. 특히 대용량 데이터 처리에 요구되는 높은 쓰루풋을 제공하지 못했습니다. 많은 비용을 들여 스토리지에서부터 서버까지의 데이터 전송속도를 향상시키고자 SAN, Infiniband 등 다양한 고속 스토리지 네트워크를 적용하고 스토리지 자체 I/O 성능을 높이더라도, 결국 대용량 데이터가 한 곳에 몰려 스토리지 영역이 병목이 되는 근본적인 문제점을 안고 있었습니다.
이처럼 복수의 어플리케이션 서버들이 통합 스토리지 레이어에 데이터를 저장하는 구조를 SMP (Symmetric Multi-Processing) 이라고 합니다. SMP 구조에서는 데이터 용량이나 성능 향상을 위해서는 장비 자체의 성능을 높이는 scale up 방식을 주로 선택해야만 했습니다. 문제는 scale up을 해도 근본적인 문제가 해결되지 않는다는 것입니다.
1990년대 후반 신흥 닷컴기업들이 부상하면서 상황이 변하기 시작했습니다. 부족한 자금으로 어마어마한 데이터를 저장하고 처리해야 했던 그들은 SMP의 근본적인 한계를 벗어나기 위해 새로운 대안을 만들었습니다. 스토리지에 집중된 데이터를 복수의 서버에 분산시키고, 이 서버들을 하나의 클러스터로 구성해 분산된 소량의 데이터를 서버들이 병렬적으로 처리하는 플랫폼을 개발하여 사용하기 시작하였습니다. 이러한 분산 병렬 아키텍쳐는 단위 트랜잭션 처리 성능은 떨어지지만 대용량 데이터를 저장하고 처리하는데 있어서는 비용면에서나 성능면에서 SMP보다 월등히 뛰어났습니다. 또한 scale out 방식으로 데이터 증가 및 성능 향상에도 유연하였으며 상용 하드웨어를 활용해 비용면에서도 장점이 있었습니다. 이러한 분산 병렬 아키텍쳐를 MPP (Massive Parallel Processing) 이라고 합니다.
가장 큰 문제는 비용입니다. 저장해야 할 데이터의 양이 폭발적으로 늘어난 데다 어플리케이션의 수와 종류도 늘어나 스토리지의 증설과 신규도입 비용이 IT 예산에서 너무나 큰 비중을 차지하게 되었습니다. 스토리지 가상화를 통한 씬 프로비져닝 (Thin provisioning) 을 적용해 스토리지 가용률을 높이는 데에도 한계가 발생할 수밖에 없었습니다.
두번째 문제는 성능입니다. 특히 대용량 데이터 처리에 요구되는 높은 쓰루풋을 제공하지 못했습니다. 많은 비용을 들여 스토리지에서부터 서버까지의 데이터 전송속도를 향상시키고자 SAN, Infiniband 등 다양한 고속 스토리지 네트워크를 적용하고 스토리지 자체 I/O 성능을 높이더라도, 결국 대용량 데이터가 한 곳에 몰려 스토리지 영역이 병목이 되는 근본적인 문제점을 안고 있었습니다.
이처럼 복수의 어플리케이션 서버들이 통합 스토리지 레이어에 데이터를 저장하는 구조를 SMP (Symmetric Multi-Processing) 이라고 합니다. SMP 구조에서는 데이터 용량이나 성능 향상을 위해서는 장비 자체의 성능을 높이는 scale up 방식을 주로 선택해야만 했습니다. 문제는 scale up을 해도 근본적인 문제가 해결되지 않는다는 것입니다.
1990년대 후반 신흥 닷컴기업들이 부상하면서 상황이 변하기 시작했습니다. 부족한 자금으로 어마어마한 데이터를 저장하고 처리해야 했던 그들은 SMP의 근본적인 한계를 벗어나기 위해 새로운 대안을 만들었습니다. 스토리지에 집중된 데이터를 복수의 서버에 분산시키고, 이 서버들을 하나의 클러스터로 구성해 분산된 소량의 데이터를 서버들이 병렬적으로 처리하는 플랫폼을 개발하여 사용하기 시작하였습니다. 이러한 분산 병렬 아키텍쳐는 단위 트랜잭션 처리 성능은 떨어지지만 대용량 데이터를 저장하고 처리하는데 있어서는 비용면에서나 성능면에서 SMP보다 월등히 뛰어났습니다. 또한 scale out 방식으로 데이터 증가 및 성능 향상에도 유연하였으며 상용 하드웨어를 활용해 비용면에서도 장점이 있었습니다. 이러한 분산 병렬 아키텍쳐를 MPP (Massive Parallel Processing) 이라고 합니다.
MPP 전성시대
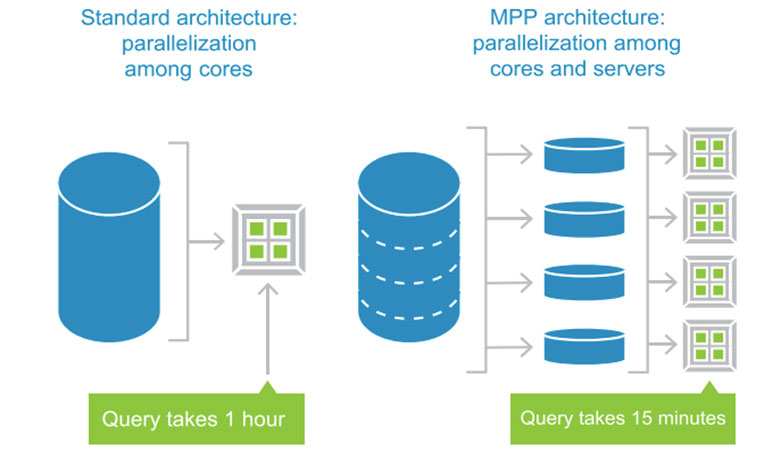
빅데이터 시대의 데이터 시스템에서 MPP 아키텍쳐 기반의 데이터 저장소는 사실상 표준이 되었습니다. 단순히 데이터 저장의 비용 효율성 측면에서만이 아니라 대용량 데이터에 대한 질의 성능 역시 MPP가 SMP에 비해 월등합니다. 왜 그럴까요? 예를 들어, 10권짜리 백과사전에서 ‘데이터’ 라는 단어가 총 몇 번 등장하는가를 계산하는 작업이 있다고 합시다. 한 명의 눈과 손이 아주 빠른 박사급 인재와 열 명의 평범한 중학생들이 이 작업을 동시에 시작하면 어느 쪽이 더 빠르고 정확하게 결과를 내어 놓을까요? 한 명의 박사는 백과사전 10권을 모두 훑어야 하고, 중학생들은 한 명 당 한 권씩 훑어 각각의 결과를 취합하면 됩니다. 제 아무리 한 명의 박사의 지능이 높고 일처리가 빠르다 하더라도 결과는 당연히 열 명의 중학생의 승리입니다. 동일한 원리로 MPP는 SMP에 비해 대용량 데이터 처리의 일괄 처리에 있어 월등히 뛰어납니다.
SSOT와 MVOT
MPP 기반 데이터 저장소를 확보한다고 해서 모든 것이 해결되는 것이 아닙니다. 데이터 저장이라는 단계에서 데이터를 비용 효율적으로 저장한다는 것은 너무나 당연한 이야기이자 사실 고민의 대상조차 되지 못합니다. 정말 중요한 과제는 어떤 데이터를 어느 위치에 어떻게 저장하여 데이터의 고립과 중복을 최소화하고, 데이터의 정합성을 유지하며, 다운스트림 유저들의 분석 요건을 만족시킬 것인가입니다. 물론 이 과제는 데이터 저장 단계에서만 고민해야 할 문제가 아니라 데이터 엔지니어링 전반에 걸쳐 고민해야 할 한 조직의 데이터 전략이지만, 데이터 저장과 관련된 요소가 가장 크게 영향을 미치므로 여기서 언급하고자 합니다.
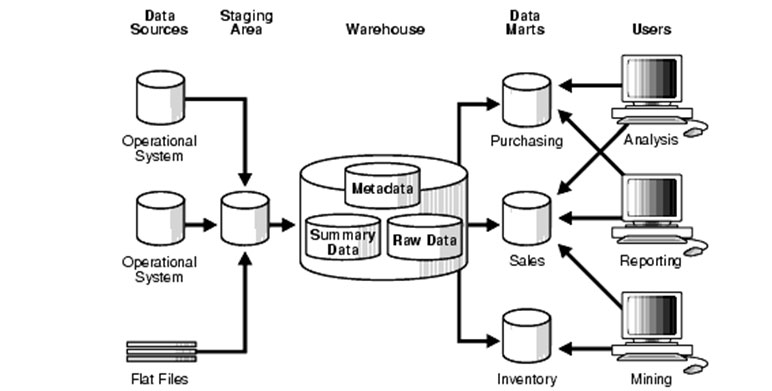
데이터의 저장 전략을 한 마디로 정의하면 두 가지 상충하는 요건의 균형점을 찾는 것입니다. 여기서 두 가지 상충하는 요건들이 바로 SSOT (Single Source of Truth) 와 MVOT (Multiple Versions of Truth) 입니다. SSOT란 조직 내 데이터 자원에 대한 일괄적이고 강력한 통제를 통해 정합성, 통일성, 보안을 확보해 잘못된 데이터가 유통되는 것을 방지하고자 하나의 데이터 원본을 저장하는 방식입니다. MVOT란 이와 반대로 다양한 부서의 다양한 상황과 데이터 요건을 만족시키기 위해 데이터베이스를 분산시켜 필요에 따라 여러 본의 데이터를 저장하는 방식입니다. 쉽게 비유하자면 데이터 웨어하우스는 SSOT, 데이터 마트는 MVOT라고 할 수 있습니다.
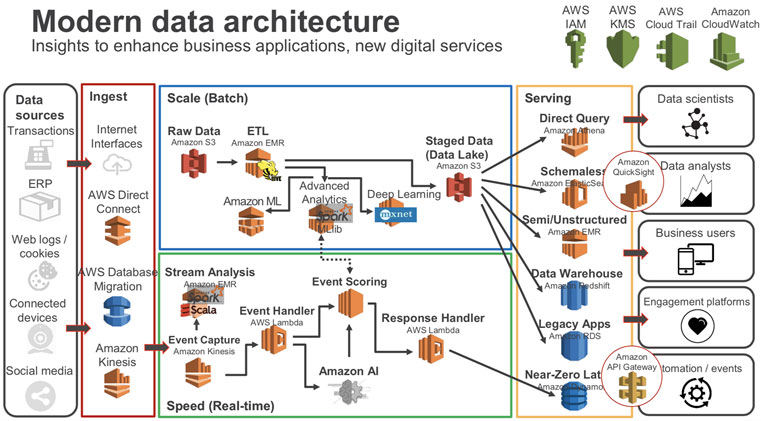
이에 대한 대안으로 등장한 개념들이 EDW (Enterprise Data Warehouse) 와 데이터 레이크 (Data Lake) 입니다. EDW와 데이터 레이크는 쉽게 말해 궁극적인 SSOT입니다. SSOT와 MVOT의 경계선이 무너져 더이상 기존의 데이터 웨어하우스들이 SSOT의 역할을 수행하지 못하게 되자 아예 조직 내 모든 데이터의 제 1 기착지를 만들어 SSOT를 구성하고 나머지 모든 시스템들은 MVOT로서 이곳의 데이터를 참조하도록 하자는 것이 기본사상입니다. 오늘날 빅데이터 플랫폼의 대부분은 이러한 사상에 따라 구성되어 있습니다. 하단의 Amazon의 상용 클라우드 기반 데이터 서비스 아키텍쳐를 참조해 보시기 바랍니다.
데이터의 저장 전략을 한 마디로 정의하면 두 가지 상충하는 요건의 균형점을 찾는 것입니다. 여기서 두 가지 상충하는 요건들이 바로 SSOT (Single Source of Truth) 와 MVOT (Multiple Versions of Truth) 입니다. SSOT란 조직 내 데이터 자원에 대한 일괄적이고 강력한 통제를 통해 정합성, 통일성, 보안을 확보해 잘못된 데이터가 유통되는 것을 방지하고자 하나의 데이터 원본을 저장하는 방식입니다. MVOT란 이와 반대로 다양한 부서의 다양한 상황과 데이터 요건을 만족시키기 위해 데이터베이스를 분산시켜 필요에 따라 여러 본의 데이터를 저장하는 방식입니다. 쉽게 비유하자면 데이터 웨어하우스는 SSOT, 데이터 마트는 MVOT라고 할 수 있습니다.
이에 대한 대안으로 등장한 개념들이 EDW (Enterprise Data Warehouse) 와 데이터 레이크 (Data Lake) 입니다. EDW와 데이터 레이크는 쉽게 말해 궁극적인 SSOT입니다. SSOT와 MVOT의 경계선이 무너져 더이상 기존의 데이터 웨어하우스들이 SSOT의 역할을 수행하지 못하게 되자 아예 조직 내 모든 데이터의 제 1 기착지를 만들어 SSOT를 구성하고 나머지 모든 시스템들은 MVOT로서 이곳의 데이터를 참조하도록 하자는 것이 기본사상입니다. 오늘날 빅데이터 플랫폼의 대부분은 이러한 사상에 따라 구성되어 있습니다. 하단의 Amazon의 상용 클라우드 기반 데이터 서비스 아키텍쳐를 참조해 보시기 바랍니다.
호환성
모든 데이터 저장소는 업스트림의 데이터 유입 및 정제 툴, 다운스트림의 데이터 분석 및 시각화 툴 등 다양한 관련 플랫폼과의 연계가 필수적입니다. 그렇지 않다면 그저 고립된 데이터 사일로에 불과하게 됩니다. 조직 내 데이터가 원활히 유통되고 조합될 때만이 데이터는 전략적 자원으로서 빛을 발하므로 고립된 데이터 사일로는 모든 데이터 시스템에서 가장 경계하고 기피해야 할 대상입니다.
관련 제품 : Vertica, IBM IIAS
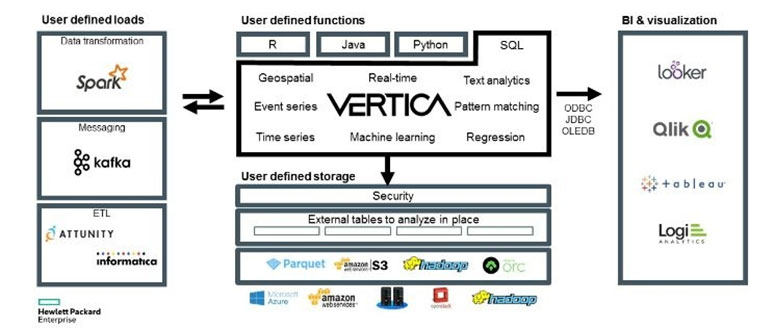
관련 제품 : Vertica, IBM IIAS